
Los Chatbots son el tópico caliente del momento y amenazan con desplazarnos en muchas áreas, pero a pesar de su excelente escritura y capacidad de generar contenidos, realmente estos no entienden el contenido de lo que dicen, en su lugar suenan cómo humanos debido a la cantidad inhumana de conocimientos que han ingerido en tan poco tiempo, y si se preguntan de dónde sale toda esa información, podemos responder como el pequeño Timmy de los Padrinos Mágicos: Internet. Con eso en mente, sería interesante conocer las fuentes de dónde ChatGPT y otros Chatbots basados en IA adquieren sus conocimientos, pues eso condiciona directamente el cómo responden a los usuarios
Afortunadamente ya podemos hacernos una buena idea de lo anterior mencionado, pues el diario The Washington Post junto al instituto Allen Institute for AI tomaron un vistazo muy detenido a uno de los conjuntos de datos de dónde se nutren estas inteligencias artificiales.
Estos son los sitios web de los que se alimentan los ChatBots como ChatGPT
Para ser específicos, estamos hablando de C4 o Colossal Clean Crawled Corpus de Google, una base de datos creada por Common Crawl, y cuya data se utilizó para desarrollar modelos de lenguaje como T5 de Google y LLaMA de Facebook. La misma alberga una gigantesca snapshot de 15 millones de sitios web.
Sea como sea, esta es la lista de los 15 sitios web más usados para entrenar modelos de lenguaje:
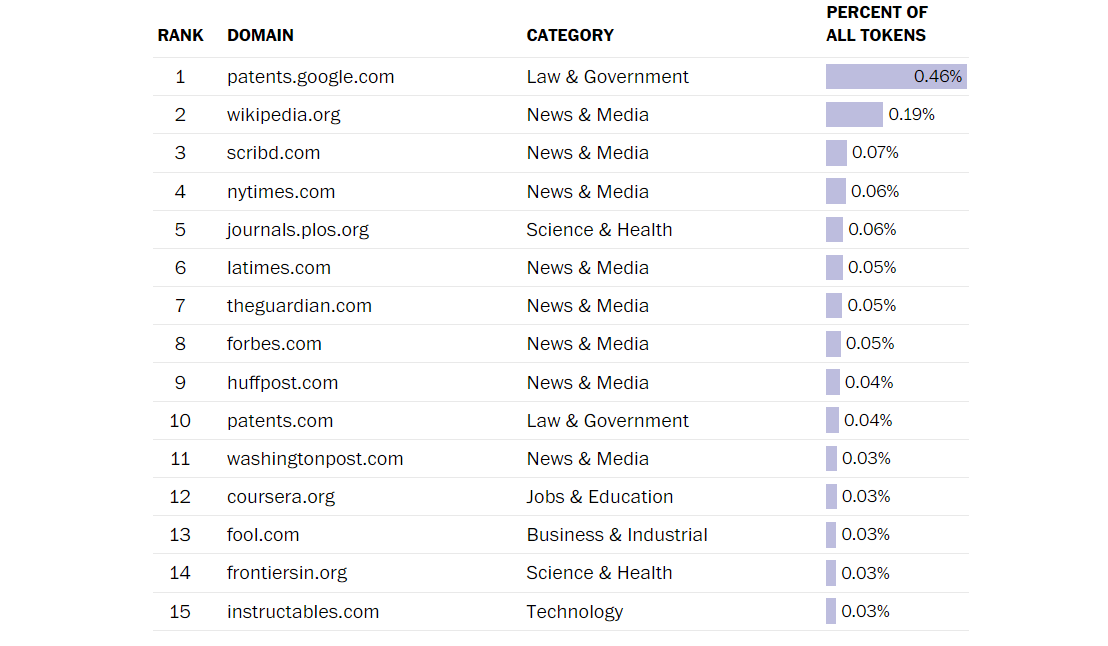
Patents.google.com encabeza la lista, algo bastante curioso al tratarse de un sitio web que recopila patentes emitidas en todo el mundo. En segundo lugar, tenemos a Wikipedia, una elección obvia para cualquiera en busca de información.
El tercer lugar pertenece a Scribd.com, otro sitio web que rebosa de documentos de todo tipo. El resto de las posiciones del top 15 están ocupadas por medios de noticia de gran reputación, como lo son Forbes.com, The Guardian y el propio Washington Post.
¿Está siendo tu sitio utilizado para entrenar IAs?
Una preocupación totalmente justificada de los dueños de sitios web es que estén usando sus posts para entrenar IAs bajo sus propias narices. Afortunadamente, ya hay una manera de salir de dudas, puesto que el Washington Post dispuso una herramienta que nos permite consultar las webs recogidas en el conjunto de datos C4. La misma funciona con un porcentaje de tokens o fichas que representan fragmentos de texto usado para procesar información desorganizada.
Con todo eso dicho, este no es el fin de la historia, de hecho, es solo el comienzo, pues si bien el conjunto de datos C4 es inmenso, no es el único utilizado hoy en día para alimentar estas IAs. Como referencia, el conjunto de datos empleado para entrenar a ChatGPT-3 contiene 40 veces la cantidad de contenido web recopilado en el Colossal Clean Crawled Corpus de Google.
También hay muchas preocupaciones flotando en Internet sobre el contenido en sí con el que se está entrenando a esas IAs, pues encontrar información personal sobre personas identificables, material con derechos de autor y otros datos obtenidos sin consentimiento es altamente posible.
De igual manera, se encontró bastante contenido problemático que supuestamente debió haber sido filtrado por Google en el conjunto de datos C4, estamos hablando de contenido pornográfico, racista y de incitación al odio, pero eso es una historia para otro día.






